
A Glimpse into The Daily Life of a Data Scientist
A couple of weeks ago, I had a discussion with a co-worker regarding a project I was involved in, I felt that there was no clear understanding of the daily challenges data scientists face. Few days later, I was at Rstudio::Conf 2017 where I met lots of data scientists from academia and industry. Later on, I described one of the conference’s positive side effects as “group therapy”, where one could see how others face the same challenges and struggle with similar issues. So it was like a personal sanity check!
When I came back to work, I decided to share with other teams more details about my daily work to help them understand the nature of my job, set their expectations and avoid conflicts. So I sent them a shorter version of the following.
| "We are living in a Kafkaesque universe when we are doing data stuff." [1] | |
| Josh Wills, Head of data engineering at Slack |
As the role of data scientists evolve in different industries, it might be hard for some individuals or teams to get exactly what data scientists are doing, what they need, what challenges they face and why do they take time to come up with the simplest outputs. Or simply what on earth are we doing in the first place?
Here is a glimpse into the world of data science as I know it through the eyes of experienced data scientists and based on my short experience. Hopefully, this will help us avoid getting into the infinite loop of sadness as things get more complex.
So I will try to address the following questions:
-
What accounts for the most of the work of data scientists?
-
Why things go slow sometimes even if data seems to be available?
-
What are the main characteristics of good data analysis? And what are the common critical issues?
What accounts for the most of the work of data scientists?
| "Practically, because of the diversity of data, you spend a lot of your time being a data janitor, before you can get to the cool, sexy things that got you into the field in the first place" [2] | |
| Matt Mohebbi, Data scientist and co-founder of Iodine |
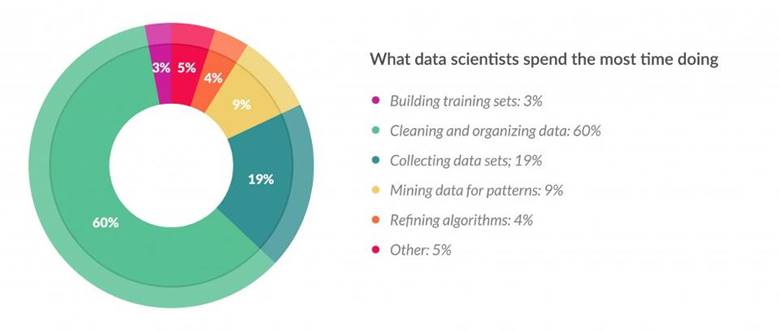
Most of the time, the other teams see the tip of the iceberg. They see the results; the nice visualizations, the models, the patterns,..etc. However, as per a survey conducted by CrowdFlower[3] , “data scientists spend, on average, around 80% of their time on preparing and managing data for analysis”. And since this part is really critical and painful, researchers and data scientists try to create tools and systems to make it easier. For instance, Taming Data; a recent article on MIT news, mentions Data Civilizer system as a trial to “decrease the grunt work needed to facilitate the analysis of data in the wild” [4].
Why things go slow sometimes even if data seems to be available?
| "It's an absolute myth that you can send an algorithm over raw data and have insights pop up." [2] | |
| Jeffrey Heer, Professor of computer science at the University of Washington and a co-founder of Trifacta |
Although data seems to be available all the time, one can still struggle to put it in the right format, which seems a simple quick task but the underlying known/unknown issues makes it really time consuming sometimes. From my experience, I could list some issues:
Reading Data
| "Reading data can be horrific." | |
| Hadley Wickham, Chief Scientist at RStudio |
It might be surprising that people keep developing packages in different languages just to read data in the desired format, handle missing values, handle encoding issues, assign the right data classes,..etc. Every time a new source is imported, a new issue might pop-up. One could identify it, spend some time tracking it or even lose one’s sanity to find out!
Preparing Data
| "Tidy datasets are all alike but every messy dataset is messy in its own way." [6] | |
| Hadley Wickham, Chief Scientist at RStudio |
It is recommended, in almost every type of analysis to start with tidy data, i.e. data organized in form where:
-
Each variable forms a column
-
Each observation forms a row
-
Each type of observational unit forms a table [6]
In most of the cases, data does not come in such format or come from different sources. One can spend an awful lot of time working on merging and transforming data from messy to tidy.
Tracking Changes in Data Sources
| "You prepared your data for a certain purpose, but then you learn something new, and the purpose changes."[2] | |
| Cathy O'Neil |
During the journey of data analysis, one might need to change directions, go back to reinvestigate, or take a new path due to new discoveries, especially if one starts with exploratory analysis where everything is possible.
The following issues makes things harder:
-
Updates in data sources that are not synchronized with the data used in the analysis. In such cases, one might struggle to keep track of all changes.
-
Change in purpose that was initially directing the work. With this change, one might need to put data in a different form, add more sources, track the changes, fix the scripts, test them, etc.
Processing Data
| "If you torture the data long enough, it will confess." | |
| Ronald Coase |
Data processing can be a really time consuming, it can even be a mutual torturing activity, however this depends on several factors such as data size, resources (hardware, software, internet connection!), purpose of analysis, using extracts versus live data, required accuracy and much more!
At some points, one does not have control over all the factors. One could get stuck with a slow chunk of code that imposes certain limitations. Several approaches could be adopted according to the available time, resources and urgency of task. One could try to profiling and optimizing the code, scaling up and getting more resources, getting back to data preparation and putting it in another form or pre-aggregate some values if possible, or just tolerate slowness if other solutions will take a longer time!
Delivering Preliminary Results
| "An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem." | |
| John Tukey |
Here comes the final part where others see the results, and start to feel that the data scientists were not messing up. To get the desired results and avoid going into loops or repeating analysis a data scientist needs:
-
Clear realistic expectations: Tell me what is the minimum acceptable accuracy, what tradeoffs you can tolerate and what time limit you cannot exceed. I will start exploring and tell you what I can deliver, how long do I need to give you an update, what resources do I need (extra data, data entry personnel…etc.).
-
Involvement of all stakeholders: If a product manager, developers and business people are involved, I would like to get them to understand the hurdles I face, the pop-up issues and the sources of delay. We could find out that the initial target was not realistic or will be time consuming, so we’ll adjust and compromise.
Interpreting Results
| "In real life there is no such person as the average man. There are only particular men, women and children, each with his or her inborn idiosyncrasies of mind and body." | |
| Aldous Huxley Brave New World Revisisted |
Whenever we deal with data; especially when it is about people, it is hard to summarize everything in one single measure. Sometimes people ask about the “average number of users who do x”, look at R^2^, or other measures and jump to a conclusion. But, in most of the cases, one needs to dig deeper, combine different measures, go to a lower level of granularity, etc. to make better inference and this may take some time.
What are the main characteristics of good data analysis?
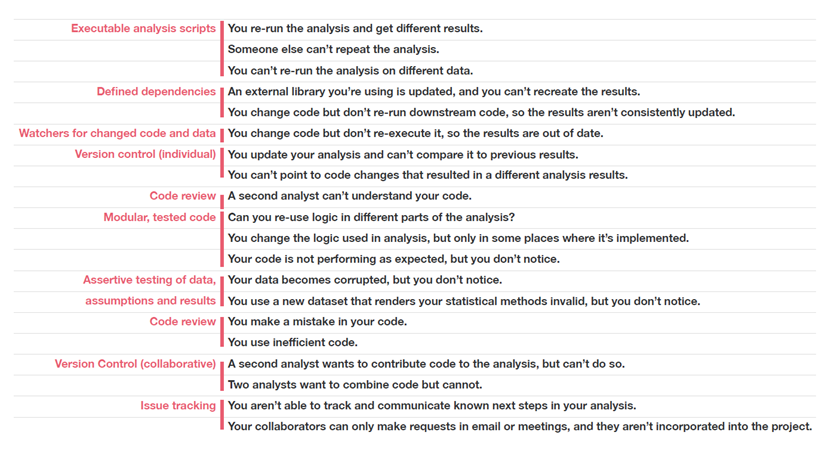
In her talk, Opinionated Analysis Development at Rstudio:Conf 2017, Hilary parker, a data analyst at StitchFix, highlighted that a good data analysis should be Reproducible, Accurate, and Collaborative:
-
Reproducible: Some of the analyses are required once, others are required more or grow with time. So making reproducible analysis, parameterized reports, and maintaining code makes it easier to avoid lots of issues. This would take sometime at the beginning , but saves time later especially if the underlying data changes.
-
Accurate It might take some time to write an efficient code, one sometimes hurry at the beginning to come up with results under pressure. But eventually as things get more complex, one gets obliged to stop and clean the code to be able to keep moving forward. So starting with an accurate code would always be a good practice.
-
Collaborative This is important in case more than one person collaborate on the same code/files.
Hilary Parker also grouped the most common issues under the previous three points

She also suggested approaches to address each group
In Conclusion
The daily life of data scientists is full of challenges. It certainly differs from one to another, depending on the industry, organization, type of data, and many factors. But having this understood by other teams, and considering the hidden part of the iceberg, might help. And I encourage every individual/team with a dynamic or new role to communicate with others and explain their challenging hidden part of their jobs.
Resources
1-Data Engineering and Data Science: Bridging the Gap-DataEDGE 2016, Josh Wills, Slack
2-For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights, Steve Lohr, NYT
5- Taming Data, Larry Hardesty, MIT News Office
6- Tidy Data, Hadley Wickham, Rstudio
7- Opinionated Analysis Development, Hilary Parker, Stitch Fix